
发布日期:2024-10-05 15:06 点击次数:211

据中国品牌节主席、品牌联盟董事长王永介绍,本届品牌节采取“1950”模式,将举办一场大型开幕式,电商博览会、企业家运动会、荣耀盛典、品牌之旅等9场重要活动配资门户,以及平行论坛、企业家双边会谈、品牌品鉴会等50余场丰富多彩的活动。此外,还将发布《2024中国品牌节华谱奖》《2024中国品牌500强》《2024世界品牌500强》《2024中国创新品牌500强》《2024广东品牌500强》等10余项榜单,对品牌强国建设中表现突出的企业与个人进行推介与表彰。
在Computex 2024的发布会上,AMD推出了全新的Zen 5架构,包括桌面端的锐龙9000系以及面向移动端的锐龙AI 300系处理器。但当时并没有透露关于架构的太多信息,只是说了产品的型号命名和参数规格,而在上周举行的AMD技术日活动上他们详细介绍了Zen 5、RDNA 3.5和XDNA 2的技术细节,还包括了锐龙9000和锐龙AI 300系处理器的一些关键性能数据。
AMD新一代处理器的核心:Zen 5架构解析

本次锐龙9000桌面处理器以及锐龙AI 300系移动处理器均使用Zen 5架构,而这两款处理器都会在本月上市,具体时间是锐龙AI 300的笔记本会在7月28日,而锐龙9000处理器则是7月31日。

Zen 5架构的改进方向大体可归纳为:每周期可执行更多指令;更宽的调度和执行单元;数据缓存带宽翻倍;更强的AI加速性能。

先来看前端的改进,Zen 5直接升级成双管道预取和解码,搭配高级分支预测技术,可有效减少延迟、提高准确性和吞吐量,指令缓存的延迟和带宽也得到改进,这些措施有效提高了数据流和数据处理速度,且不会牺牲准确性。

整数执行单元加宽了指令分派和执行通道,分配和引退从以往Zen架构的每时钟周期6条指令增加到8条,以往的旧Zen架构整数执行单元包括4个ALU和3个AGU,而Zen 5则增加到6个ALU和4个AGU,它们均配备一体化调度器,这样Zen 5就拥有更大的执行窗口,在更复杂的计算工作负载下会有更好表现。此外核心缓冲区从320条目增加到448条目,以更好地处理更广的调度和执行所产生的更多的未命中。

浮点执行单元获得重大更新,AMD自上代Zen 4开始支持AVX-512指令集,但那是使用256位SIMD用两个时钟周期来执行AVX-512指令的,而Zen 5则可提供完整的512位数据位宽,搭配6管线与2周期延迟的FADD,可处理更多浮点指令,在CPU执行一些AI模型时,能够显著提高反应速度与效能,面对未来各种AI应用。

缓存方面,一级数据缓存容量从32KB增加到48KB,宽度也从8路增加到12路,每周期4次读取2次写入,这让一级缓存与浮点单元的最大带宽直接比上代翻倍,改善了数据预取的效率。
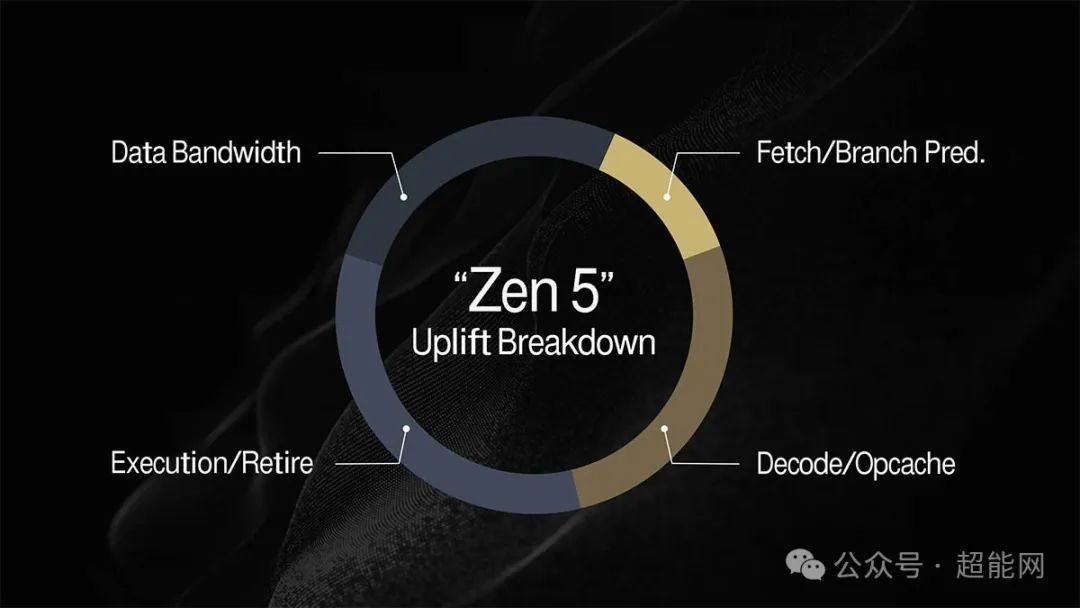

根据AMD给出的数据,Zen 5架构的性能提升主要由数据带宽、执行/退休、解码/指令缓存以及获取/分支预测这四大部分改进相互促进而成的,而Zen 5的IPC较Zen 4平均提升了16%之多,而使用VNNI的机械学习单核性能则比Zen 4提升了32%,使用AVX-512的AES-XTS加密负载单核性能则提升了35%。

除了在7月会上市的两款消费级处理器外,采用Zen 5内核的第五代EPYC也将会在今年下半年上市,目前的Zen 5 CCD以及锐龙AI 300将会采用台积电4nm工艺生产,而未来更紧凑、更节能的Zen 5c则会采用台积电3nm工艺。从图片可以看出EPYC Turin最多16个Zen 5 CCD,按每个CCD有8个核心计算的话最多128核,而采用Zen 5c CCD的版本则最多192核。

在Zen 5之后,Zen 6也在路上了
锐龙AI 300的核显:RDNA 3.5架构

今年AMD有没有RDNA 4这点我还不知道,但这RDNA 3.5是AMD专门为Strix Point移动处理器所打造的,针对每瓦能效、内存每bit效能以及更长的电池续航时间进行架构优化,它将被用在Radeon 800M系列核显上。
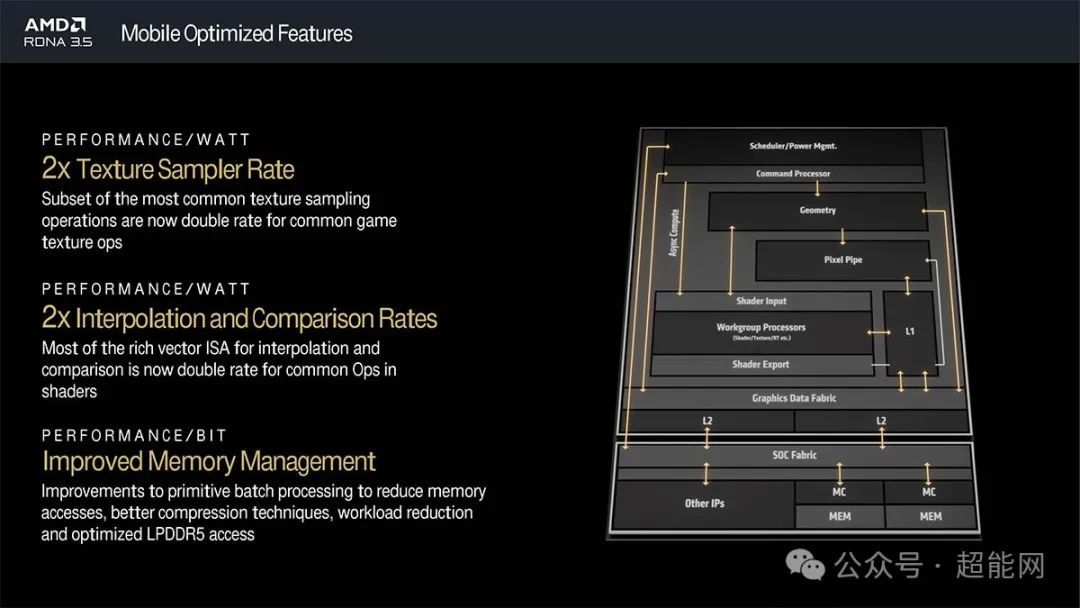
RDNA 3.5较原来的RDNA 3相比有两倍的纹理采样率和插值与比较速率,前者意味着GPU拥有前代的两倍性能,在游戏过程中纹理和图形的细节和清晰度得到增强,理论上有助于改善细节纹理,在高分辨率时更有冗余,而后者则可以更好地呈现高质量图形细节。
还引进了更先进的内存管理技术,提高了内存每bit的操作效能,降低了对LPDDR5内存访问频率,意味着读写更快,总体上也更节能,延长笔记本的电池续航力。

根据官方的数据,在同样是15W性能释放下,Radeon 800M的3DMark Timespy得分比上代提升了32%,而Night Raid跑分则提升了19%。以上就是关于RDNA 3.5的内容,说真的AMD并没有透露太多的细节信息。
新NPU算力高达50 TOPS:XDNA 2架构
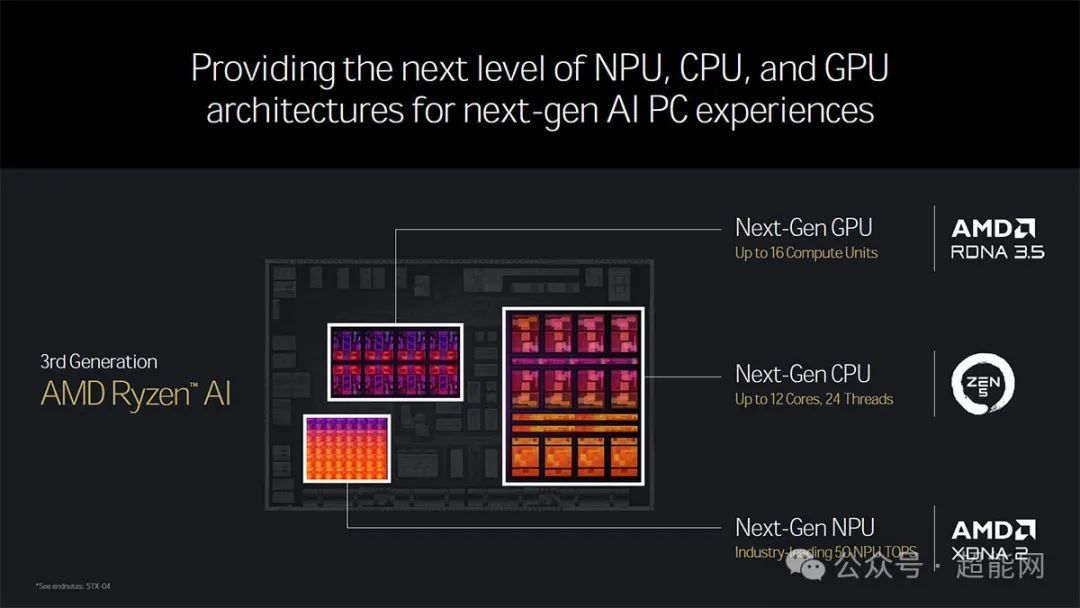
Intel在宣传Lunar Lake时说它有CPU、GPU、NPU三个AI内核,实际上AMD自锐龙7040系列处理器开始就是这种结构,而现在Strix Point则配备了全新的XDNA 2架构NPU,可提供高达50 TOPS的AI算力,比锐龙7040的10 TOPS和锐龙8040系的16 TOPS提升非常大。

上图是XNDA架构NPU和传统的多核处理器的对比,说真的XDNA的这结构其实更像GPU这种平衡处理器,XDNA设计将灵活的计算与自适应内存层次结构结合起来,内部拥有大量互联的AI引擎,有着弹性的运算单元与内存调度制度。

每个AI引擎通过可编程互联节点进行分区控制,可进行灵活分区使用,包括空间分区和时间分区,空间分区就如上图的例子那样,两列AI引擎负责实时视频、两列负责实时音频、四列负责内容创作应用。时间分区则适合大模型,可以整体先后执行不同的任务,比如先全力处理大语言模型,然后全部转向视频编辑。


XDNA 2拥有32个AI引擎,每列拥有4个AI引擎,MAC数量较上代翻倍,缓存容量增加1.6倍,支持Block FP16块状浮点格式,支持非线性增强。NPU可根据任务的轻重程度以列为单位开启AI引擎,在轻任务下可以关闭部分核心,从而节约功耗,能效比初代提高了一倍。性能方面,XDNA 2可提供50 TOPS的AI算力,是上代的5倍。
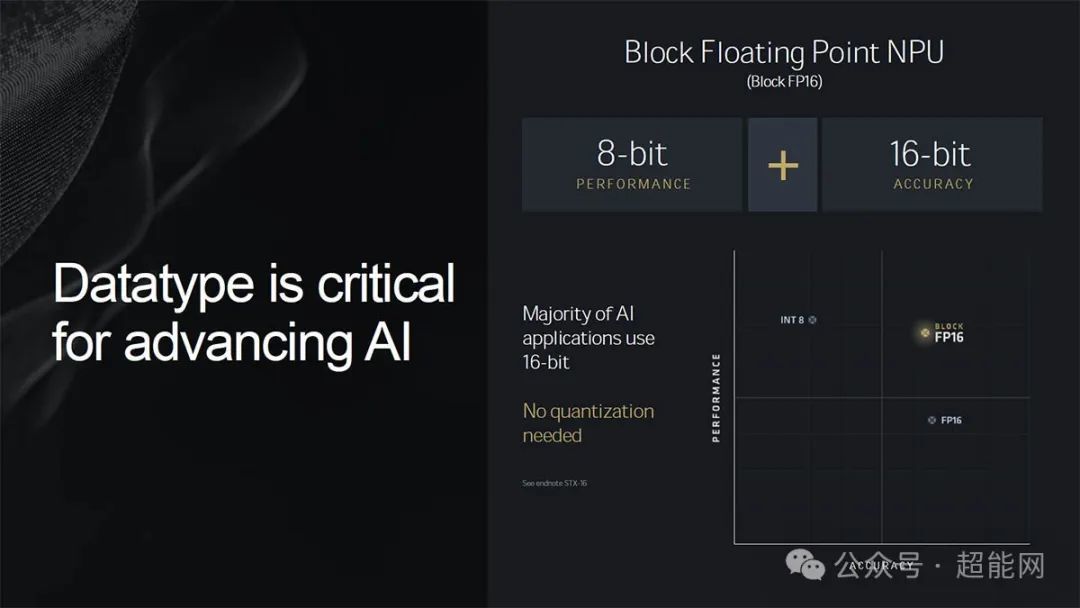
XDNA 2架构行业首创支持Block FP16浮点格式,对于AI运算来说数据类型至关重要,Int 8有较高的计算效能但精确度相对较低,而FP16则有较高的精确度但效能较低,而Block FP16则可实现Int 8的性能和FP16的精度。

AMD对比了Strix Point和苹果M4 ANE、Intel Lunar Lake和高通骁龙Elite X处理器运行FP16数据的峰值算力,性能要高出很多,Lunar Lake的48 TOPS是基于Int 8数据的,跑FP16大概减半。

Block FP16数据类型精准度其实仅比FP32睇那么一点点,而且对于开发商来说,可以相当容易的把模型转化为FP16、FP32和BF16等数据类型。

在大语言模型Llama v2 7B的FP16量化模型的性能测试中,最新的锐龙AI 300处理器NPU的响应速度是酷睿Ultra 7 155H的5倍。
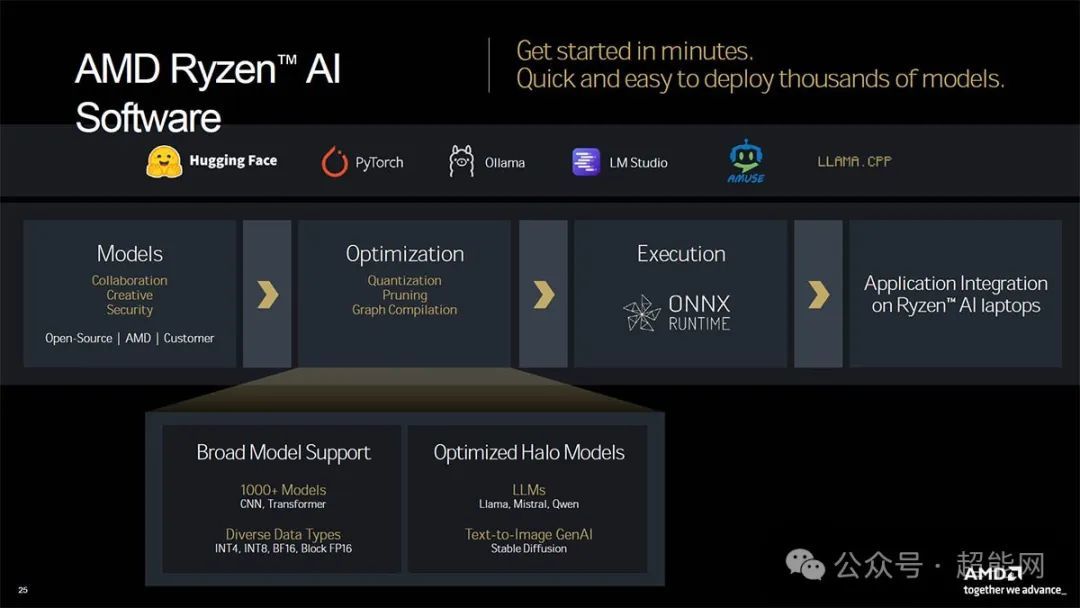
AMD也计划推出Ryzen AI Software以支持各种模型并对其优化,并采用ONNX Runtime执行,让未来搭载锐龙AI处理器的笔记本电脑具备更多的AI应用功能。
锐龙9000桌面处理器

其实锐龙9000系列桌面处理器的规格早在Computex 2024上就公布了,基本和当年的锐龙7000是完全一样的,包括:
锐龙9 9950X,16核32线程,最高频率5.7GHz,64MB L3缓存,170W TDP;
锐龙9 9900X,12核24线程,最高频率5.6GHz,64MB L3缓存,120W TDP;
锐龙7 9700X,8核16线程,最高频率5.5GHz,32MB L3缓存,65W TDP;
锐龙5 9600X,6核12线程,最高频率5.4GHz,32MB L3缓存,65W TDP;
两颗锐龙9是双CCD,而锐龙7和锐龙5则是单CCD,而且锐龙9 9950X、锐龙9 9900X的最高频率和锐龙9 7950X、锐龙9 7900X也是一样的,而锐龙7 9700X和锐龙5 9600X则比锐龙7000的两款同型号的高100MHz,而这些处理器的上市时间敲定在7月31日。


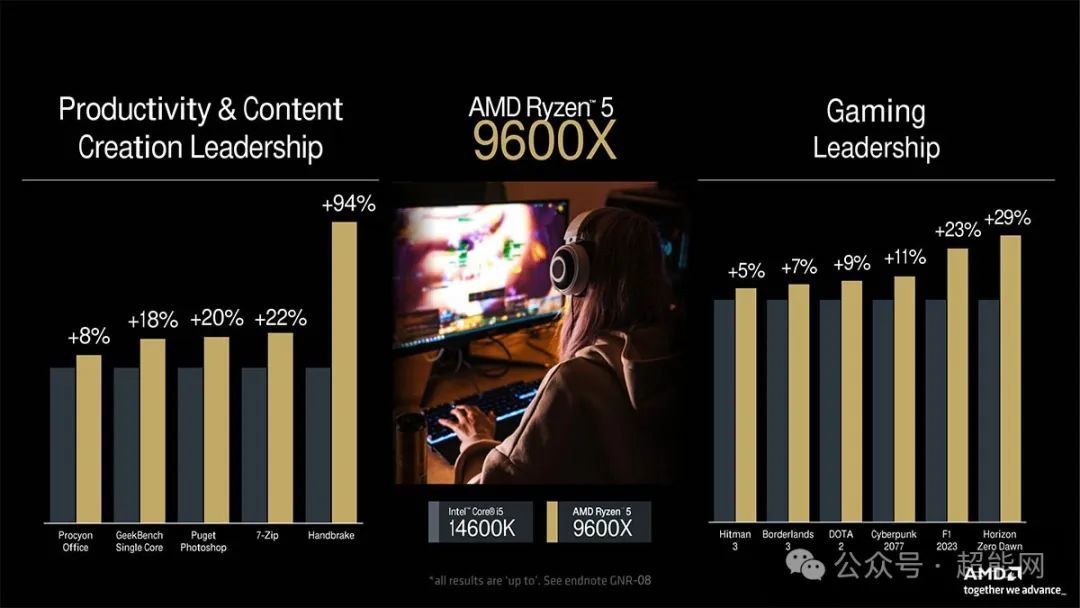
由于Intel的新一代桌面处理器估计要10月才上市,这次AMD给锐龙9 9900X找的对手是现在Intel现在的旗舰酷睿i9-14900K,而锐龙7 9700X的对手则是酷睿i7-14700K,锐龙5 9600X是酷睿i5-14600K,具体的性能对比大家看图就好了,至于顶级的锐龙9 9950X,就等着对手的下一代处理器来挑战。
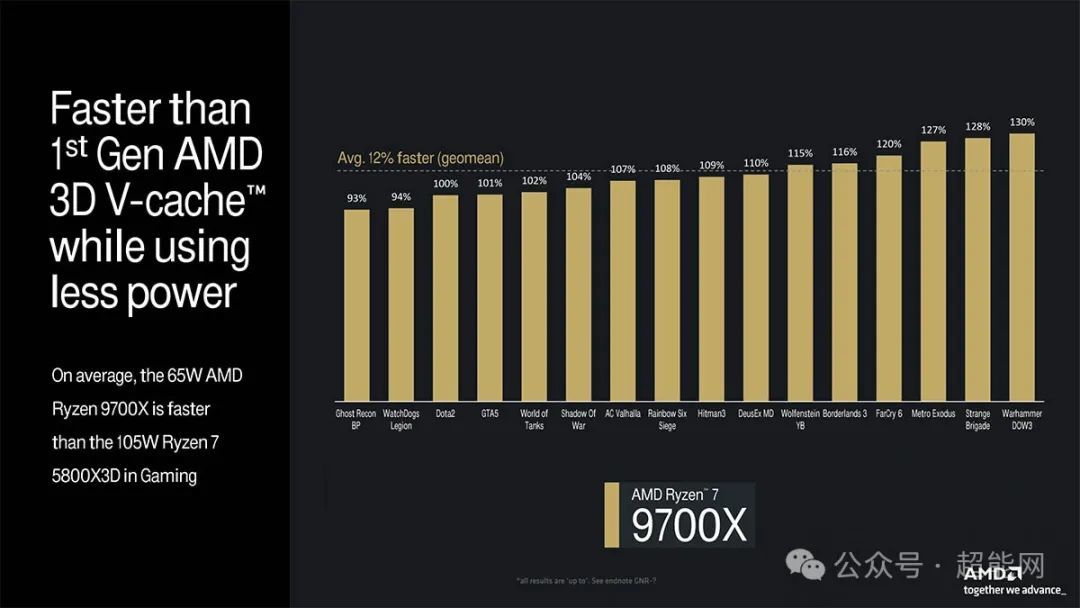
AMD没给出锐龙7 9700X与锐龙7 7800X3D的性能对比,而是放出了锐龙7 5800X3D的对比,根据官方数据,65W的锐龙7 9700X在游戏性能上领先于105W的锐龙7 5800X3D,平均要快12%,而且功耗更低,实际上锐龙9000X3D应该也不远了,到时候再和锐龙7 7800X3D对比吧。

除了最顶级的锐龙9 9950X外,这代每个型号的TDP都要比上代有所降低,性能方面则有11%到22%不同幅度的增长,此外得益于新架构和新工艺,处理器的热阻降低了15%,同TDP下温度要比上代低7℃,对散热器的要求明显降低。

内存支持也有所改进,默认的JEDEC内存可支持DDR5-5600,但新的AGESEA可让内存频率直达DDR5-8000,同时支持内存实时超频,可在系统内对内存时序经行更改,可随时使用Ryzen Master软件进行内存超频,也可随时切回默认状态。

CPU超频可直接交给PBO,可实现6%~15%的性能提升
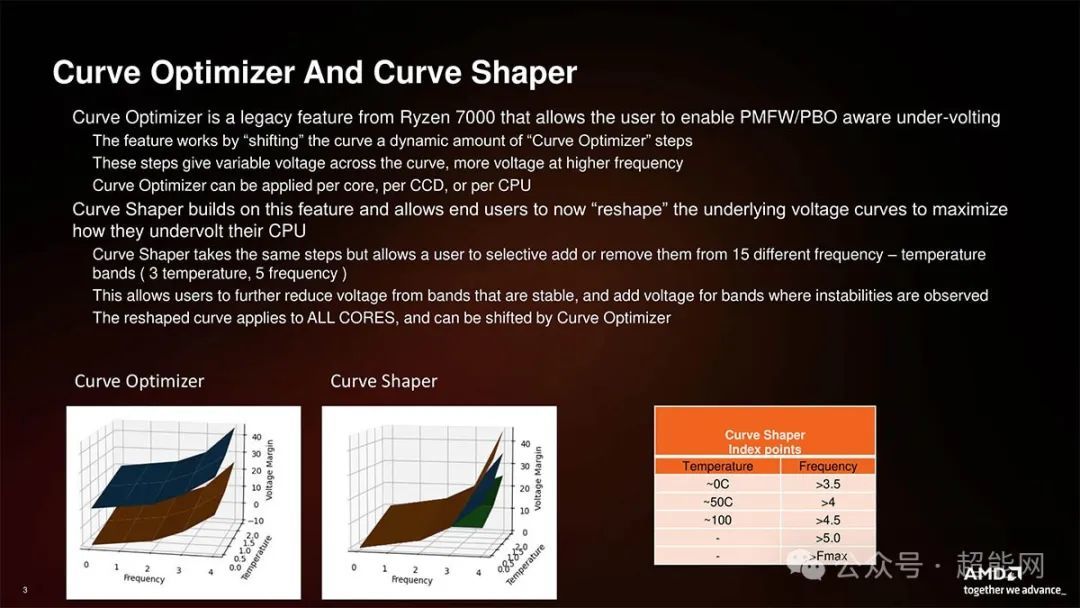
此外AMD在原有的Curve Opitimizer功能基础上推出Curve Shaper功能,可进一步允许玩家最大化调整降压曲线,可提供最多15组频率与温度的组合,玩家可以在稳定区降低电压并在必要时增加电压,这允许玩家把锐龙9000处理器的潜力挖掘到极致,这设置适用于所有核心,不能单独对某个核心进行调节。

主板方面,且和之前透露的消息差别不大,X870E是双芯片,与X670E相比就是多了USB4的支持。X870变成了单芯片,现在GPU和M.2都强制支持PCIe 5.0,同时也支持USB4,可看作是多了USB4的B650E。B850其实就是B650的平替,但显卡插槽升级支持PCIe 5.0。B840大家把它理解成A620就行了,不支持CPU超频但支持内存超频,只支持USB 10Gbps,显卡和M.2口都是PCIe 4.0的,其他扩展则是PCIe 3.0。
锐龙AI 300处理器
其实上面所说的RDNA 3.5以及XDNA 2都是锐龙AI 300移动处理器的独享内容,锐龙9000桌面处理器并不会配备这些,它的IO-Die还是锐龙7000上面那个,所以核显也是RDNA 2架构的。

其实到这里Strix Point也没多少东西可说了,首批提供了锐龙AI 9 HX 370和锐龙AI 9 365两款产品。其采用了混合架构设计,CPU部分包括了Zen 5和Zen 5c架构的内核,与Intel异构不同,Zen 5、Zen 5c还是完全相同的架构,IPC和ISA是完全相同的,不同之处在于核心频率以及搭配的L3缓存容量。
锐龙AI 9 HX 370拥有4个Zen 5和8个Zen 5c,共24线程,配备24MB L3缓存,基础频率2.0GHz,最大加速频率5.1GHz,配备16组CU的Radeon 890M核显。
锐龙AI 9 HX 365拥有4个Zen 5和6个Zen 5c,共20线程,配备24MB L3缓存,基础频率2.0GHz,最大加速频率5.0GHz,配备12组CU的Radeon 880M核显。
两者均配备50 TOPS的XDNA2架构NPU,TPD从15~54W可调。
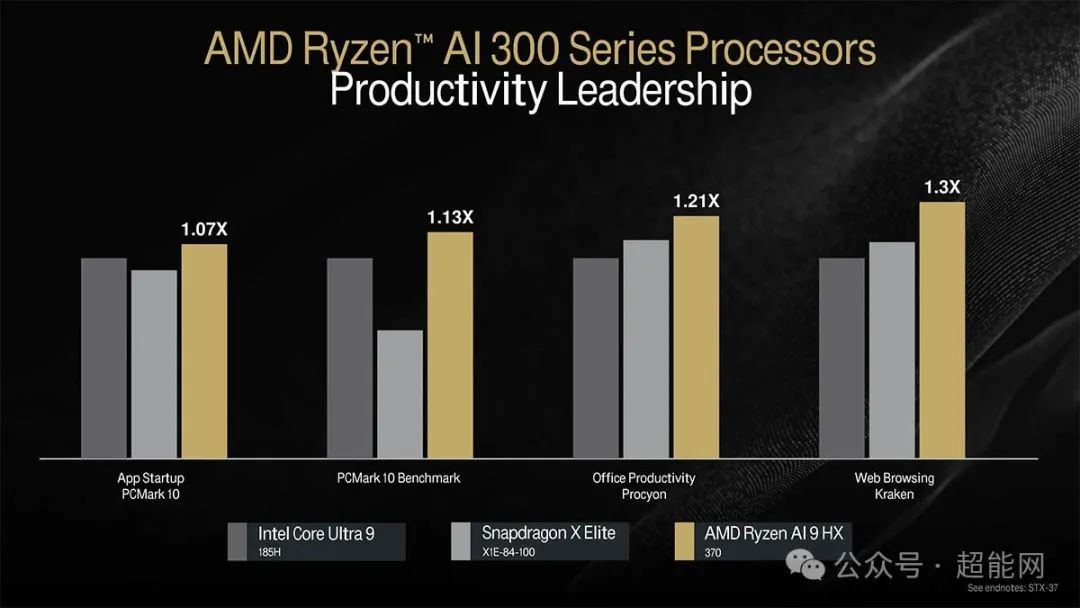
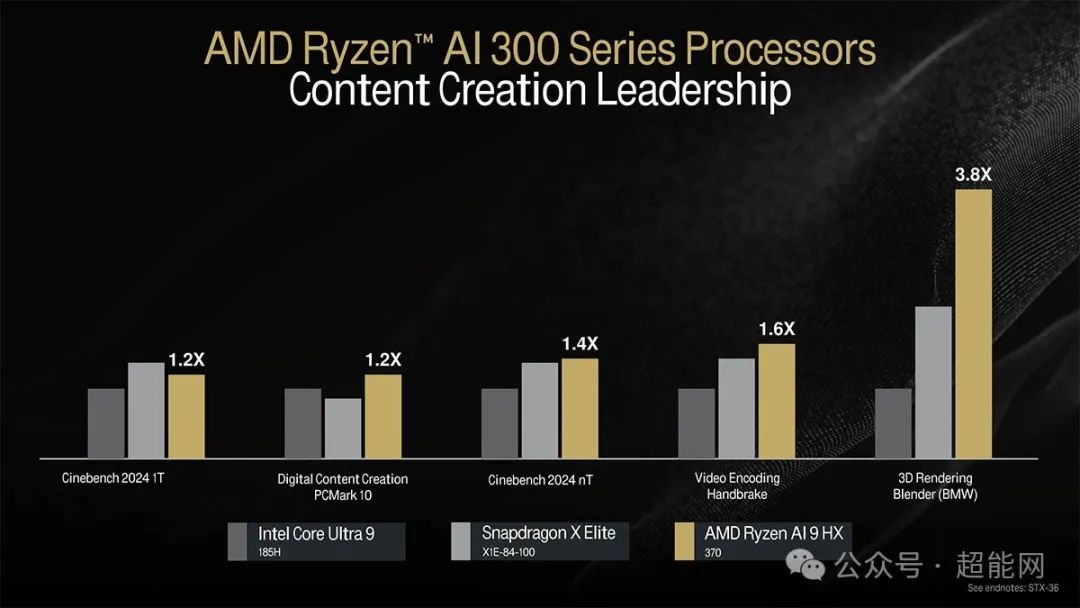
AMD拿锐龙AI 9 HX 370对比了Intel酷睿Ultra 9 185H以及高通的骁龙X Elite处理器,不论生产力还是创作力方面的性能都是要领先对手的。

游戏性能更是AMD处理器的拿手好戏,而且高通X Elite处理器在游戏上出现了不少兼容性问题,根本不能运行,ARM架构在Windows系统下还是存在较严重的兼容性问题,而AMD新一代RDNA 3.5架构Radeon 890M核显则可在高画质下流畅运行不少3A游戏。
总结
AMD新一代Zen 5架构的锐龙AI 300笔记本会在7月28日上市,而锐龙9000处理器则是7月31日,虽然上面的PPT对比的都是Intel当前这代的产品,但大家应该都清楚它们真正的对手是Intel下一代的Arrow Lake和Luner Lake,当然了Luner Lake其实并不是一个赛道上的东西,但难免被大家拿来对比。
由于这次Lion Cove架构P核和Skymont架构E核改动很大配资门户,再加上大家都使用台积电4nm工艺,到时的性能对比肯定很精彩,只不过AMD这次确实有时间优势,因为搭载Luner Lake处理器的笔记本大概率要等到9月才上市,而Arrow Lake桌面版本则要等到10月,移动版更是要明年初。AMD这次早至少两个月不说,而且还让他们搭上了暑期销售旺季这班车,打对手一个先手,至于到时会不会被反推还很难说,反正可以确定的是AMD还有X3D这个后手藏着。
